Rethinking our UI
Taskcluster, a set of microservices designed to run automated builds and tests, has been open source since the very beginning. It is not Mozilla-specific and in principle, can be reused in other organizations. However, the current implementation is not designed to be easily redeployable. We hardcode a bunch of stuff and have our own configs included in the source files.
In this post, I will discuss some changes we are doing to the front end in our road to a more redeployable Taskcluster capable of supporting other organizations.
Style Guide
A user interface is easy to mess up. You can start a project with one style and end with another. The issue is amplified when you have multiple members contributing to the same project. Not following a style guide has made the tools site exercise poor UX practices such as discrepancies with the layout.
Example: Inconsistent layout
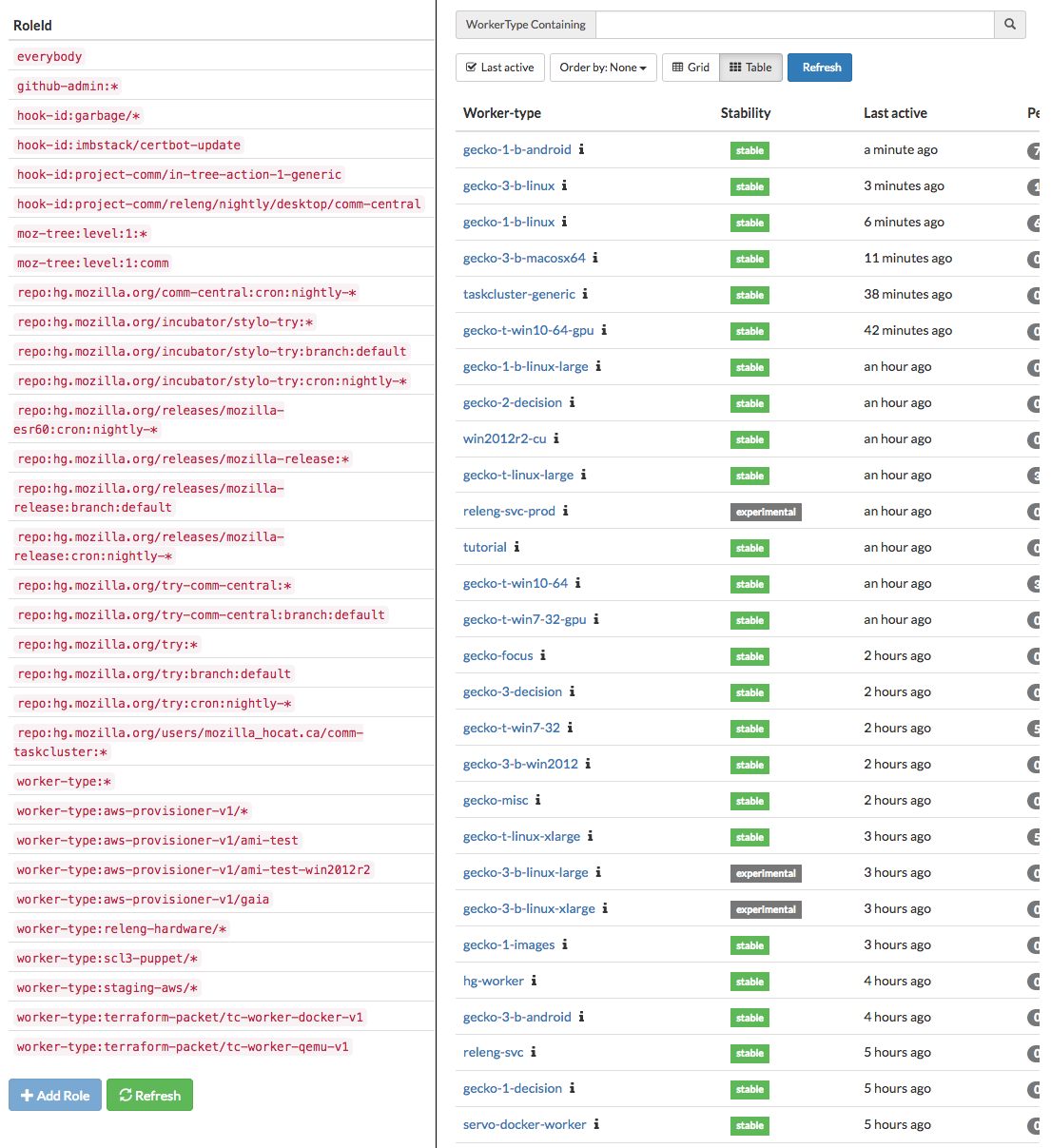 Inconsistent layout in the roles (left) and provisioners (right) views
Inconsistent layout in the roles (left) and provisioners (right) views
In the roles view, the button for creating a new role or refreshing the list moves to the end of the page as new roles keep getting added. As a consequence, users need to scroll to the bottom of the page to see the actions. On the other hand, the set of actions in the provisioners view are positioned above the list.
To ensure a consistent and better experience to the user, we are adding a style
guide to the front end to help unify the UX of views and to aid in following a common style guide.
We plan on using react-styleguidist to generate a
guide that outlines best practices, shows component propTypes and displays live editable examples.
GraphQL
The tools site fetches an enormous amount of data and occasionally performs many requests at a time. We sometimes are forced to put a low limit to the data allowed to be stored in an entity in order to stay away from experiencing a hanging UI. An example where a low limit is enforced is in the worker page. When a user first navigates to this view:
- The client sends an initial request to fetch information about the worker. The response includes the list of most recent tasks the worker ran.
- For each recent task, two additional requests are triggered — one to get information about that task and the other to get information about the task’s status[1].
The above control flow results in a plethora of HTTP requests with heavy responses affecting significantly the initial loading time of the view. Because of that, we previously had made a decision to limit the queue service to only store a worker’s 20 most recent tasks.
Fortunately, it turns out GraphQL can help in making the UI feel smoother by allowing us to ask for what we need and get many APIs’ response in a single request.
From http://graphql.org/:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
I like to think about GraphQL in graphs:
- Client sends a web request to the single endpoint
/graphql— the graph. The request will only fetch what it wants. Nothing more, nothing less. - Server does its magic and returns the requested data.
We decided to add a GraphQL layer that sits on top of our APIs to help improve the user experience.
Why GraphQL?
Here’s a couple of reasons:
- Reduced bandwidth
- Declarative
- Self documented
Reduced Bandwidth
With GraphQL, a view can get all of its data in a single round trip. Moreover, the response contains only what the view needs, hence less data transferred over the wire. On the downside, since the GraphQL layer will sit on top of our APIs instead of supporting them natively, the latency will be slightly higher than before.
Declarative
With GraphQL you define what you want, not how you get it. The tools site is written in React; when designing using React components, it’s recommended to think in terms of what the component should look like in its new state instead of how you want to accomplish the result. With GraphQL being declarative as well, the overall structure of the application is better preserved and makes it easier to reason about as a whole.
Self Documented
GraphQL is self-documenting; every query, object and field comes with documentation. Because of that, GraphiQL has emerged — an interactive in-browser GraphQL IDE — which provides an experience that lets you navigate and explore your data smoothly. GraphiQL auto-completes your query which means in most cases you don’t need to refer to the documentation. Not sure what properties are available, hit (cmd|ctrl)+enter et voilà!
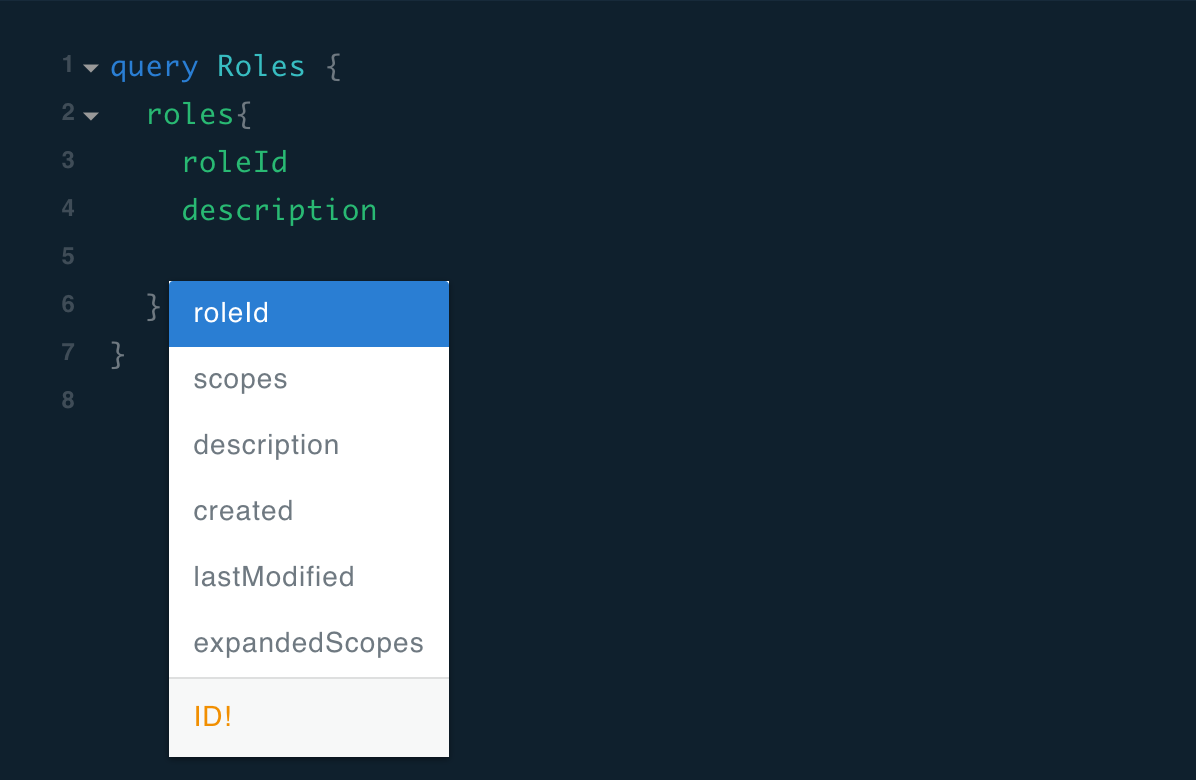 GraphiQL autocomplete feature
GraphiQL autocomplete feature
Apollo Client
Apollo Client is a GraphQL client that helps fetch data and keep the client state in sync with the server. Some of its features include batching, caching, validating, and optimizing queries based on a schema. A GraphQL client is not required but strongly recommended if you don’t want to find yourself reinventing the wheel.
Closing Remarks
Introducing a style guide will ensure consistency and coherence across the site. Organizations using Taskcluster will find it easy to keep their brand identity alive by making sure there is a common style respected. Additionally, no one will ever spend time creating a component that already exists.
GraphQL would represent a big change in the way data is handled by the front end, and we would like to bake it in from the start so we can reap its benefits immediately without needing another rewrite in the future. That said, to make sure we are not exposing any security vulnerabilities, we are going to specifically lock the GraphQL proxy down to be CORS-only limited to the web app in this first go. Supporting GraphQL natively from the APIs is a different issue which we plan to investigate in the future.