Introducing the Provisioner Explorer
For the past 3 months, I’ve been working on a new tool - long awaited - now known as the Provisioner Explorer. This is my first time as a Mozillian to own a complete project, coding both the front and back ends.
Tools used
The front end is coded in React. Also, Neutrino is used to take care of the initial configurations. If this is your first time hearing about Neutrino, you should definitely check it out. Neutrino is a command-line tool that wraps Webpack in order to support building JavaScript projects based on shared configuration presets and middleware.
The back end is coded in Node. Most of my work consisted in implementing new tables in the existing azure database. For every new table created, I created a couple of REST API endpoints.
Things I learned
For the front end, I enhanced my optimization skills. I am most proud of the optimization I did on the worker-types page where I was able to improve the first meaningful paint (FMP) by roughly 20% by lazily loading some of the components.
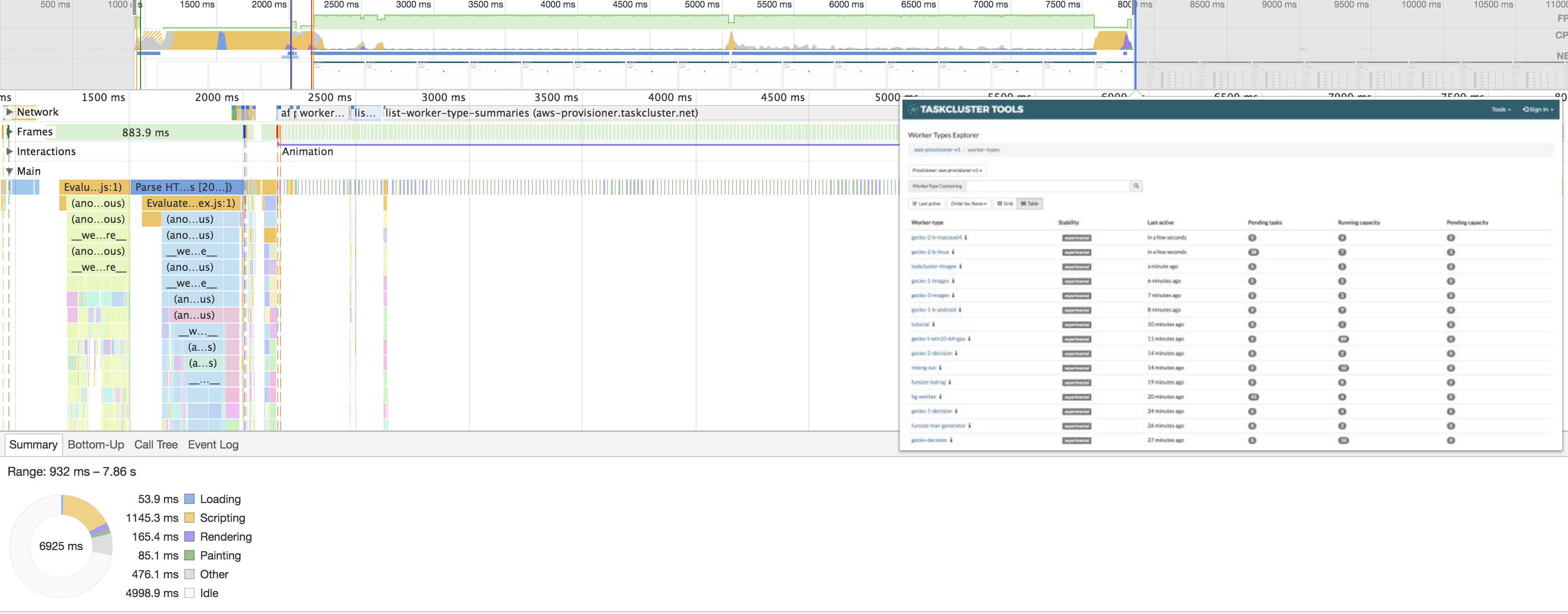 Before optimization: ~7 seconds before the FMP
Before optimization: ~7 seconds before the FMP
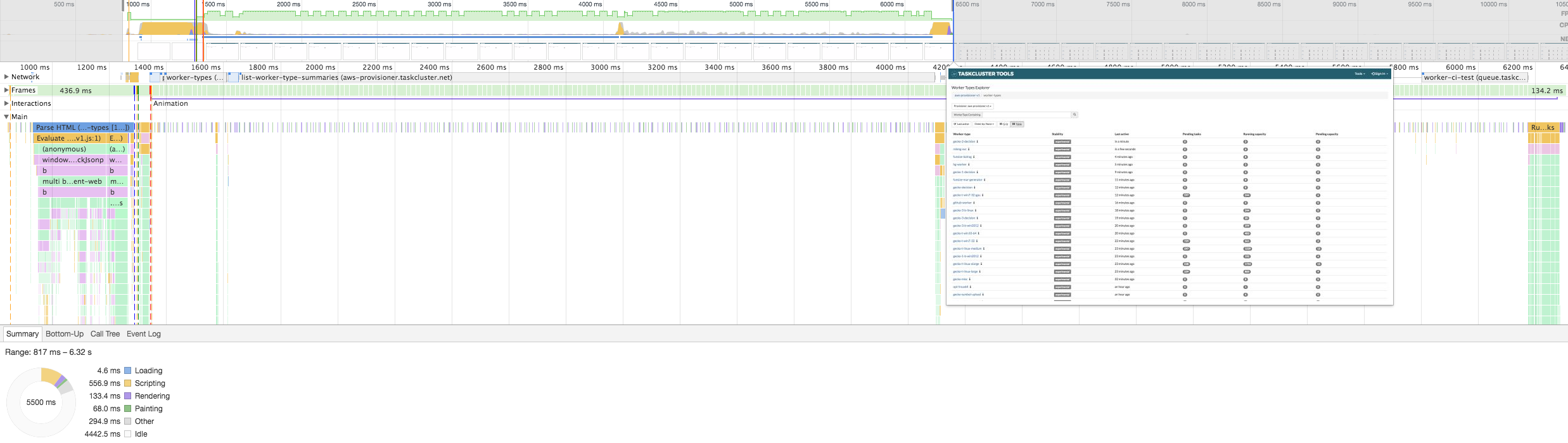 After optimization: ~5.5 seconds before the FMP
After optimization: ~5.5 seconds before the FMP
For the back end, I had my first dabble with the Microsoft Azure database. I learned how to design tables and interact with them. Furthermore, I put in interesting concepts learned at school into code. Applying theory to reality rarely happens, but when it does, it feels magical. Allow me to share two of those with you:
Amortized analysis
In my particular situation, I had a buffer implementation of an array where I was
implementing its push and pop methods. When the buffer becomes full,
one needs to perform a reallocation of memory and this is an expensive operation
since you have to move every entry to its new memory location. A similar analogy
applies when removing elements. How do we decide how much memory to allocate?
There is a trade-off between space and time. It turns out that by doubling the
array size every time we reallocate, push() has an amortized complexity of
O(1). Similarly for pop, if we reallocate the array when less than a third of
the array is used, we will have an amortized complexity of O(1). Amortized Analysis
is used for algorithms where occasionally, there will be an operation that is very
slow, however most of the other operations are faster.
Optimistic concurrency
If you read a table entity and then update it, the update will fail in Azure if someone else changed the entity in the interim. The way Azure handles it is with optimistic concurrency, where it will reload the entry and apply the modifier function again. The problem resides when you previously load the data, apply logic based on that data, then attempt to modify the database with the modifier function. The optimistic concurrency will run the modifier function again without applying all of that post logic from the first read. To overcome that, putting all of that logic inside the modifier function will solve this issue.
What can I do with it?
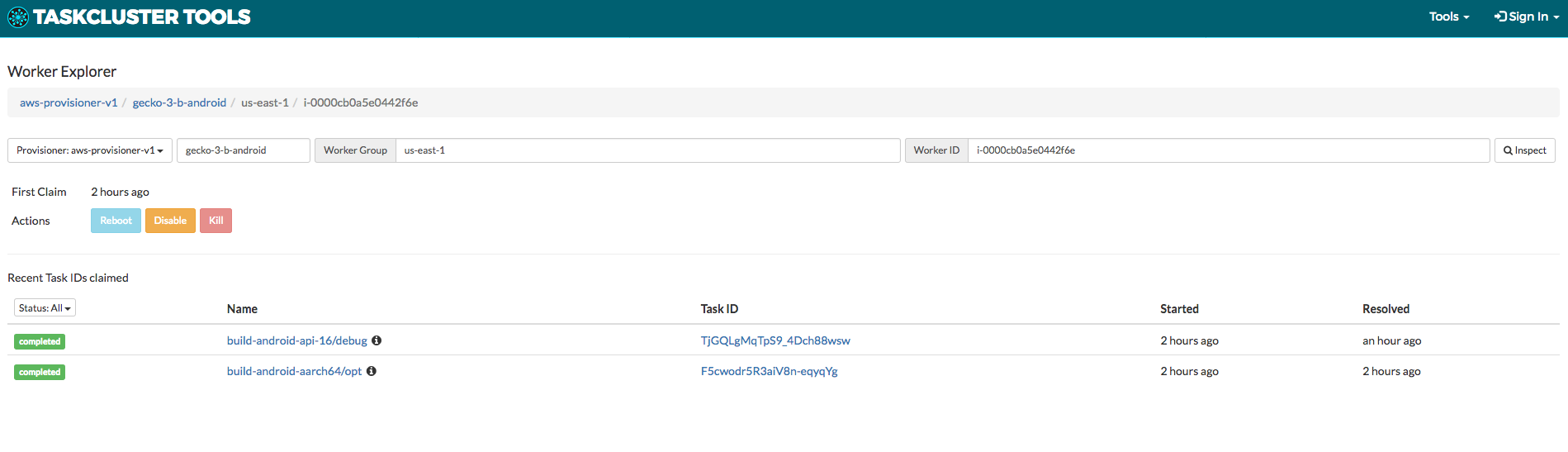
- List worker types for provisioners and see metadata like pending tasks and last date active. (e.g., https://tools.taskcluster.net/provisioners/aws-provisioner-v1/worker-types
- Drill down into a worker-type to see machines that have attempted to claim work in the last 24 hours. Also, relevant information like the first time the worker tried to claim work and details about the latest tasks claimed (start time, resolved time, status, etc.) are included. (e.g., https://tools.taskcluster.net/provisioners/aws-provisioner-v1/worker-types/gecko-t-linux-medium
- Drill down into a specific worker and perform actions against it or see the last 20 tasks it has claimed. To see an example, head over to https://tools.taskcluster.net/provisioners/aws-provisioner-v1/worker-types/gecko-t-linux-medium and click on any worker ID.
- Disable a misbehaving machine when things go wrong, such as a read-only file system, bad memory, etc. Disabling a worker allows the machine to remain alive but not accept jobs. Having the worker stop claiming tasks will make it go away (expire) eventually.
- This action, along with any action we enable in the future, will be scope protected. Disabling a machine is protected by the scope described here . We are currently identifying groups that should have this scope and how best to assign them. For now, if you need to disable a machine, but lack the scope, please enter a bug under Taskcluster::Service Request.
Future things we will add to this dashboard
- Kill action for AWS instances
- Better filtering tools
What do I do if there are problems?
- #taskcluster on IRC
- taskcluster::tools component in bugzilla